



Advancements in LLaMA2: Enhancing Multilingual Fine-Tuning for Natural Language Processing
0ea50a.jpg)
The realm of multilingual natural language processing (NLP) has grown substantially in recent years, prompting the exploration of language models that can seamlessly adapt to a myriad of languages. Among these models, LLaMA2, or the Large Language Model Archive 2, has emerged as a prominent contender for multilingual tasks. This article embarks on an exploration of the intricate landscape of multilingual fine-tuning using LLaMA2, with a keen focus on the tokenization hurdles encountered across diverse languages.
LLaMA2: Empowering Multilingual NLP
Multilingual fine-tuning represents a potent approach to develop language models capable of understanding and generating text in multiple languages. LLaMA2 stands out in this context, with its widespread adoption in the research community. Leveraging pre-trained models like LLaMA2 for various NLP tasks has become a standard practice, given their capacity to capture language nuances and context across languages.
Understanding LLaMA2 and Tokenization:

Brief overview of LLaMA2's significance in multilingual tasks:
LLaMA2, short for "Language Model for Many Languages," stands as a testament to the advances in multilingual natural language understanding. Developed as an extension of its predecessor, LLaMA, it's designed to handle an even wider array of languages, making it a valuable tool for cross-lingual applications.
Tokenization: The process of converting text into tokens, crucial for model input:
Tokenization is the fundamental process of breaking down input text into smaller units, or tokens, which serve as the building blocks for language models. These tokens allow models like LLaMA2 to understand and generate text effectively. However, the process is far from straightforward, especially when dealing with multiple languages, each with unique linguistic features and structures.
Highlighting the distinction between model and tokenizer:
It's important to differentiate between the language model itself and the tokenizer it employs. The model learns to understand the relationships between tokens, while the tokenizer is responsible for segmenting and encoding text into these tokens. The tokenizer plays a pivotal role in determining the model's input representation.
Languages Supported by LLaMA2:

A review of the languages LLaMA2 was trained on:
LLaMA2 boasts a remarkable repertoire of languages, making it a versatile tool for global applications. It covers languages like English, German, French, Chinese, Spanish, Russian, and more.
Emphasis on its proficiency in handling various languages:
LLaMA2 shines when handling European languages like English, German, and French, which share similar linguistic structures. Its proficiency extends to character-based languages like Thai and Greek, albeit with certain challenges.
Languages LLaMA2 struggles with:
Despite its wide language coverage, LLaMA2 faces difficulties with languages like Korean and Japanese, which have complex grammar and writing systems that diverge significantly from the languages it excels in.
Understanding the Model vs. Tokenizer Distinction
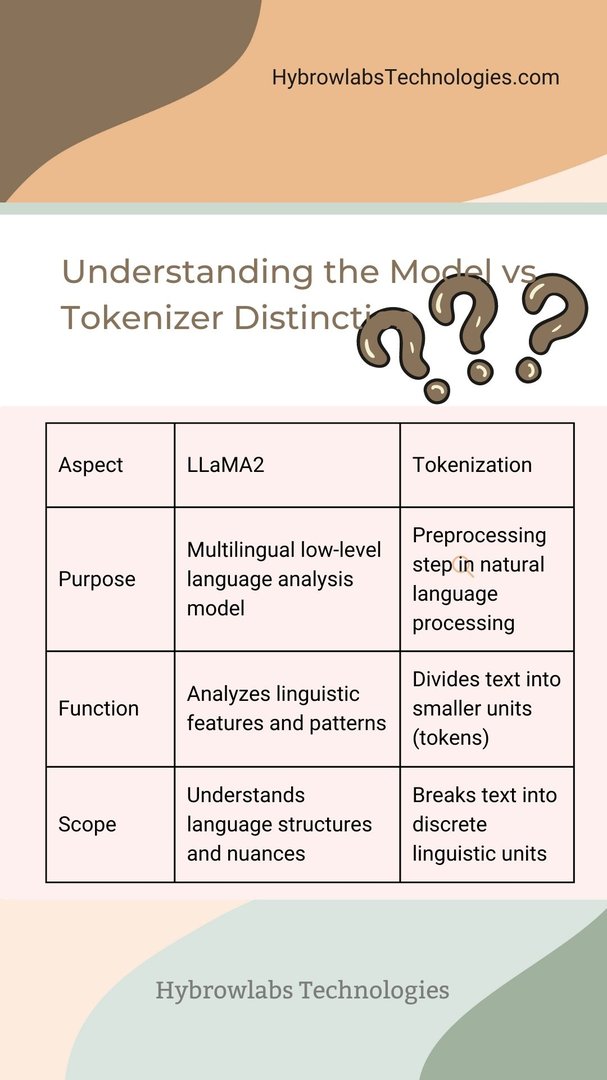
Before delving into the specifics of LLaMA2's multilingual capabilities, it's crucial to grasp the distinction between the language model and the tokenizer.
- Language Model: The language model is the core engine responsible for understanding and generating human-like text. It learns patterns, grammar, context, and semantics from the training data. LLaMA2, known for its exceptional multilingual capabilities, has been trained on a diverse range of languages.
- Tokenizer: The tokenizer, on the other hand, divides text into smaller units called tokens. These tokens are the building blocks the language model works with. An efficient tokenizer ensures that the text is properly segmented, facilitating the language model's comprehension and generation processes.
Languages Supported by LLaMA2
LLaMA2 boasts an impressive repertoire of languages it was trained on, enabling it to cater to a global audience. Let's take a closer look:
- Review of Languages: LLaMA2 was trained on a broad spectrum of languages, making it one of the most versatile multilingual models available. Its training data encompassed languages from various language families, allowing it to understand and generate text in a wide array of linguistic contexts.
- Proficiency in Handling: Among the languages LLaMA2 excels in, English, German, French, Chinese, Spanish, and Russian stand out. Its proficiency in these languages is attributed to the robust training data and well-tuned architecture, which enable it to grasp intricate nuances and produce contextually appropriate text.
- Challenges with Specific Languages: While LLaMA2 demonstrates remarkable proficiency in many languages, it's essential to acknowledge its limitations. Notably, languages with complex writing systems or intricate grammatical structures can pose tokenization challenges. Korean and Japanese, for instance, with their intricate scripts and complex honorific systems, might present difficulties for LLaMA2's tokenizer.
Demonstrating Tokenization Challenges using LLaMA2's Tokenizer
Tokenization serves as the foundational step for various natural language processing tasks such as machine translation, sentiment analysis, and named entity recognition. LLaMA2, a state-of-the-art multilingual show, utilizes its own tokenizer to fragment content into tokens that serve as input to the model. In any case, this process is not continuously direct and can lead to complications, particularly when managing dialects that have one-of-a-kind linguistic structures or scripts.
Tokenization challenges can include:
Ambiguities: Words with multiple meanings can be tokenized differently based on the context, affecting the model's understanding.
Token Length: Some languages have longer words or characters that may surpass token length limitations.
Punctuation: Different languages utilize punctuation marks distinctively, impacting token boundaries.
Morphology: Languages with rich inflectional morphology may face challenges in representing stems and affixes accurately.
Analysis of Tokenization for Different Language Categories
English
English, being a relatively straightforward language in terms of grammar and token structure, usually encounters minimal tokenization issues. Words are, for the most part isolated by spaces, and accentuation is well-defined.
European Dialects (French, German, Spanish)
Languages like French, German, and Spanish, which have a place to the Indo-European dialect family, show more complex language structure rules compared to English. These languages often have longer compound words, articles, and inflected forms that can pose tokenization challenges. The tokenizer needs to be adept at recognizing these language-specific intricacies.
Character-based Languages (Thai, Greek)
Languages like Thai and Greek are script-driven and character-based. Tokenization becomes intricate due to the absence of spaces between words. Each character can represent a distinct morpheme or meaning, leading to difficulties in determining meaningful token boundaries.
Illustration of Token Count Differences and Language Representation Difficulties
When comparing token counts across languages, disparities become apparent. Languages with agglutinative or inflected forms tend to have a higher token count since a single word can be broken down into several tokens. This can lead to potential challenges in memory usage and processing speed when training or fine-tuning models.
Moreover, certain languages have nuances that pose difficulties in representation. For instance, languages with honorifics or gender-specific forms require the tokenizer to be sensitive to such variations. The model's tokenization process must consider cultural and linguistic sensitivities to avoid misinterpretations.
Fine-Tuning Considerations

Importance of Tokenization
- Tokenization is the cornerstone of language processing, especially for multilingual models. It transforms raw text into a format that can be effectively processed by the model.
- Accurate tokenization is essential for maintaining the meaning and structure of the text, enabling the model to make meaningful predictions.
- Multilingual models like LLaMA2 are trained on diverse languages, necessitating a tokenizer that can handle the intricacies of various scripts, morphologies, and linguistic features.
Effects on Downstream Tasks and Performance
- The tokenization strategy adopted during fine-tuning can profoundly impact downstream task performance. Poor tokenization may lead to loss of information, affecting the model's predictive capabilities.
- Different languages require tailored tokenization techniques due to their linguistic diversity. Overlooking this can lead to suboptimal results for certain languages.
Tokenization Challenges and Language Feasibility
- Tokenization challenges, including morphological richness, agglutination, and word segmentation, can pose obstacles to fine-tuning for specific languages.
- Some languages lack clear word boundaries, making tokenization complex and potentially hindering model performance.
- These challenges need to be acknowledged and addressed when fine-tuning multilingual models like LLaMA2 to ensure equitable performance across languages.
Comparative Analysis with Other Models
LLaMA2's Tokenizer vs. Other Multilingual Models
- LLaMA2's tokenizer is designed to handle a wide array of languages, just like tokenizers in mBERT, XLM-R, and T5.
- A unique aspect of LLaMA2's tokenizer is its adaptability to different languages, taking into account their linguistic properties.
- Comparing tokenization strategies across models offers insights into how well each model accommodates the linguistic diversity of various languages.
Tokenization Efficiency and Language Suitability
- The efficiency of tokenization can affect the model's overall performance. LLaMA2's tokenizer strives to strike a balance between segmentation accuracy and computational efficiency.
- Different tokenizers excel with different languages, depending on the underlying linguistic characteristics. A tokenizer that performs well for one language might struggle with another.
- LLaMA2's tokenizer excels in preserving linguistic nuances and word boundaries, contributing to its suitability for a broad spectrum of languages.
Examining Bloom Models and Tokenization's Impact on Performance
- Bloom models, an extension of LLaMA2, have demonstrated remarkable performance across various languages and tasks.
- The tokenizer's impact on Bloom models is particularly intriguing. A well-crafted tokenizer can amplify the strengths of Bloom models by ensuring optimal input representation.
- Fine-tuning Bloom models with languages facing tokenization challenges may benefit from tailored tokenization strategies, maximizing performance potential.
Alternative Tokenization Approaches
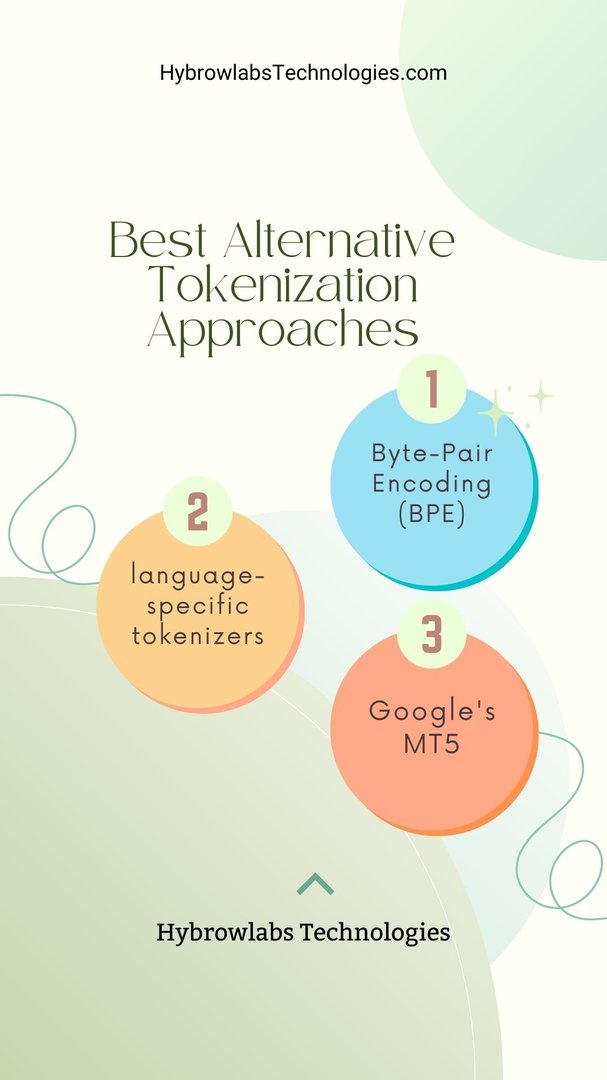
Byte-Pair Encoding (BPE): Unveiling the Power of Subword Tokenization
Tokenization is the process of breaking down a text into smaller units, typically words or subwords, for a model to understand. While LLaMA2 employs a word-level tokenization approach, alternative methods like Byte-Pair Encoding (BPE) have gained popularity. BPE focuses on subword tokenization by merging the most frequently occurring character sequences into subword units. This approach is particularly useful for languages with complex morphologies and agglutinative structures.
Exploring Models with Different Tokenizers
The adaptability of LLaMA2 is evident in its ability to accommodate various tokenization strategies. Models that are fine-tuned with language-specific tokenizers show promising results, especially for languages with distinct linguistic characteristics. This highlights the importance of tailoring tokenization methods to each language to enhance model performance.
Google's MT5: A Glimpse into Effective Multilingual Tokenization
Google's Multilingual Translation Model 5 (MT5) takes multilingual tokenization to the next level. MT5 leverages a shared vocabulary across languages, allowing for seamless transfer of linguistic knowledge. This approach enhances cross-lingual understanding and translation capabilities. By adopting a unified tokenization scheme, MT5 minimizes the discrepancies between languages and optimizes multilingual fine-tuning.
The Future of Multilingual LLaMA2
Advancements in Tokenization Techniques
The challenges faced by LLaMA2's tokenization process have spurred ongoing research in the field. Experts are investigating novel tokenization techniques that can better handle languages with unique characteristics. For instance, agglutinative languages require careful handling of morphemes to ensure accurate tokenization. Future LLaMA2 iterations are expected to incorporate such techniques to improve their multilingual capabilities.
Prospects of Larger Tokenizers
As the demand for multilingual support grows, the need for larger tokenizers becomes apparent. Incorporating a broader vocabulary enables LLaMA2 models to encompass a wider range of languages and dialects. With the advent of more efficient hardware and distributed computing, the practicality of larger tokenizers is becoming a reality. This evolution paves the way for enhanced cross-lingual comprehension and generation.
Conclusion
LLaMA2's journey through the landscape of multilingual fine-tuning has brought to light the importance of effective tokenization. As we explore alternative tokenization approaches, such as BPE, and consider models like Google's MT5, we realize the significance of tailoring tokenization methods to each language's unique characteristics. The future of multilingual LLaMA2 models holds exciting possibilities, from advancements in tokenization techniques to the incorporation of larger tokenizers. These developments promise to revolutionize the way we communicate and interact across diverse linguistic boundaries.
FAQ
1. What is tokenization, and why is it essential for multilingual LLaMA2 models?
Tokenization is the process of breaking down text into smaller units, typically words or subwords, to facilitate language model understanding. In multilingual LLaMA2 models, tokenization is crucial as it determines how the model interprets and generates text across diverse languages.
2. How does Byte-Pair Encoding (BPE) improve tokenization for multilingual models like LLaMA2?
Byte-Pair Encoding (BPE) is an alternative subword tokenization method that effectively handles languages with complex morphologies. BPE merges frequently occurring character sequences into subword units, allowing LLaMA2 to better understand languages with intricate linguistic structures.
3. Can LLaMA2 accommodate different tokenization strategies for different languages?
Yes, LLaMA2 demonstrates versatility by adapting to various tokenization methods for different languages. Language-specific tokenizers can be employed to enhance model performance, particularly for languages with distinct linguistic characteristics.
4. What sets Google's MT5 apart in terms of multilingual tokenization?
Google's Multilingual Translation Model 5 (MT5) employs a shared vocabulary across languages, leading to more consistent cross-lingual understanding and translation. This unified tokenization approach reduces discrepancies between languages and optimizes multilingual fine-tuning.
5. How might larger tokenizers contribute to the future of multilingual LLaMA2 models?
The expansion of tokenizers with larger vocabularies holds the potential to greatly enhance the language coverage of LLaMA2 models. With increased vocabulary size, these models can better handle a wider range of languages, dialects, and linguistic nuances, ultimately enabling improved cross-lingual communication and text generation.

Similar readings
a3dc85.jpg)
.jpg)

Apoorva
02-11-2025
Advanced RAG 04: Contextual Compressors & Filters
technology
fd8f11.png)


.jpg)
.jpg)
Industries We Serve
