



Mastering Information Extraction: LangChain and Kor at Your Service
In today's data-driven world, extracting valuable insights & structured information from vast amounts of unstructured textual data is crucial for informed decision-making, knowledge discovery & efficient data management. This is where information extraction comes into play, empowering organizations to unlock the potential hidden within unstructured text.
Two powerful tools, LangChain & Kor, have appeared as valuable assets in the realm of information extraction. With their advanced capabilities & specialized approaches, LangChain & Kor offer powerful solutions for mastering the extraction of meaningful information from unstructured data. From this article, you will be able to learn how to use LangChain & Kor to extract information from text. You will also be able to understand the strengths & weaknesses of both tools. This will allow you to choose the right tool for your specific needs. So Let’s start with understanding information extraction!
Understanding Information Extraction:
Information Extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents & other electronically represented sources. In most cases, this activity concerns processing human language texts by means of natural language processing.
Information Extraction is a complex task that involves a number of different steps, including:
- Text preprocessing: This step involves cleaning the text & removing any noise or irrelevant information.
- Named entity recognition (NER): This step identifies named entities in the text, such as people, organizations & locations.
- Relation extraction: This step identifies relationships between named entities, such as "John Smith works for Google" or "Google is headquartered in Mountain View, California."
- Event extraction: This step identifies events in the text, such as "Google announced a new product" or "The company was founded in 1998."
Importance Of Information Extraction In Today's Data-Driven World:

1. Knowledge Discovery:
Information extraction enables the discovery of valuable knowledge & insights from large volumes of textual data. By automatically identifying & extracting relevant information, patterns & trends, it helps uncover hidden relationships, emerging topics & valuable information that may not be readily apparent.
2. Decision Making:
Extracted information can support decision-making processes in various domains. By providing structured & organized data, information extraction helps decision-makers access relevant & timely information, enabling them to make informed choices, identify opportunities, mitigate risks & optimize business strategies.
3. Search and Retrieval:
Information extraction enhances search & retrieval capabilities by enabling efficient indexing & categorization of textual data. By extracting key entities, relationships, and attributes, it improves the accuracy & relevance of search results, making it easier to find & retrieve specific information from vast repositories of unstructured data.
4. Data Integration and Aggregation:
Extracted information can be integrated with existing databases, knowledge graphs, or data repositories, enhancing data consolidation & aggregation processes. By aligning & linking extracted entities & attributes, information extraction facilitates data integration from multiple sources, enabling comprehensive analysis & improved data management.
5. Natural Language Understanding:
Information extraction plays a vital role in natural language understanding tasks. By automatically extracting entities, relationships & events from text, it enables machines to comprehend & interpret human language more accurately. This is particularly valuable in applications such as chatbots, virtual assistants & sentiment analysis systems.
Langchain And Kor As Powerful Tools For Information Extraction:
LangChain is a rule-based information extraction framework that was developed by Stanford University. It is based on the idea of using a set of hand-crafted rules to extract information from text. LangChain has been used successfully in a variety of applications, including customer relationship management (CRM), fraud detection & compliance.
Kor is a statistical information extraction framework that was developed by the University of Washington. It is based on the idea of using machine learning to learn patterns in text that can be used to extract information. Kor has been used successfully in a variety of applications, including biomedical research, natural language processing & question-answering.
Both LangChain and Kor are powerful tools for information extraction. However, they have different strengths & weaknesses. LangChain is typically more accurate than Kor, but it is also more difficult to use. Kor is typically less accurate than LangChain, but it is easier to use.
The best choice of tool for a particular application will depend on the specific requirements of the application. If accuracy is the most important factor, then LangChain is a good choice. If ease of use is the most important factor, then Kor is a good choice.
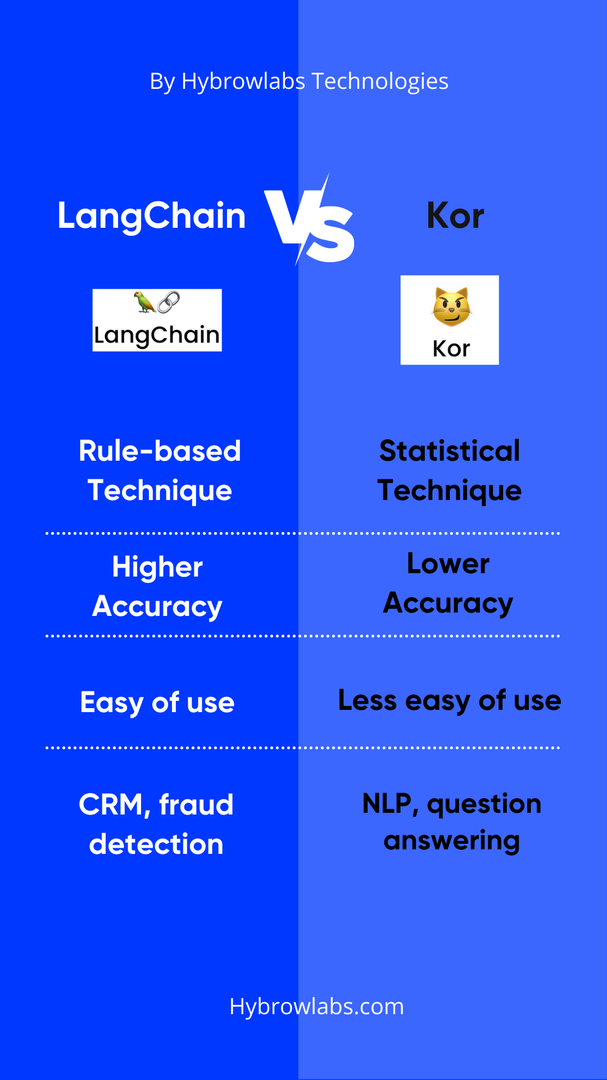
Here is a table that summarizes the key differences between LangChain and Kor:
| Feature | LangChain | Kor |
| Approach | Rule-based | Statistical |
| Accuracy | Higher | Lower |
| Ease of use | Lower | Higher |
| Applications | CRM, fraud detection, compliance | Biomedical research, natural language processing, question answering |
What Are The Key Challenges In Information Extraction?
1. Vagueness:
Natural language is naturally unclear, with words & phrases often having multiple meanings. Resolving vagueness & determining the correct interpretation of entities, relationships & events is a significant challenge in information extraction.
2. Clarification of named entities:
Identifying & classifying named entities accurately is crucial for information extraction. However, named entities can have variations, aliases & ambiguous references, requiring robust techniques for disambiguation & linking to relevant knowledge bases.
3. Domain and Context Dependency:
Information extraction tasks often depend on the specific domain or context. Extracting information accurately & effectively across diverse domains & contexts requires domain-specific knowledge, adaptable models & sufficient training data.
4. Handling Noisy and Incomplete Data:
Textual data can be noisy, containing grammatical errors, misspellings, abbreviations & informal language. Dealing with such noisy data & extracting meaningful information from incomplete or unstructured sources is a significant challenge.
These are just some of the key challenges in information extraction. As the amount of text continues to grow, these challenges are likely to become even more pronounced. However, research in information extraction is ongoing & there are several promising new techniques developed to address these challenges.
Here are some of the promising new approaches to information extraction:
- Deep learning: Deep learning is a powerful machine learning technique that has been used to achieve state-of-the-art results in a variety of NLP tasks, including information extraction. Deep learning models can learn complex patterns in text that can extract information.
- Transfer learning: Transfer learning is a technique that can be used to improve the performance of information extraction systems by using pre-trained models. Pre-trained models have been trained on a large corpus of text and have learned to extract general patterns in text. These patterns can then be used to improve the performance of information extraction systems on new tasks.
- Embeddings: Embeddings are a type of representation that can be used to represent words & phrases in a vector space. Embeddings can be used to capture the semantic similarity between words & phrases, which can be used to improve the performance of information extraction systems.
Role Of Natural Language Processing (NLP) In Information Extraction:

Natural language processing (NLP) is a field of computer science that deals with the interaction between computers & human (natural) languages. NLP has a wide range of applications, including information extraction.
Information extraction is the task of automatically extracting structured information from unstructured or semi-structured text. This information can then be stored in a database or knowledge graph for further processing.
Natural Language Processing (NLP) plays a vital role in information extraction by enabling machines to understand, interpret & extract meaningful information from human language. NLP techniques are used to preprocess text, tokenize & tag words, identify named entities, parse sentence structure, resolve coreference, assign semantic roles & perform sentiment analysis. By leveraging NLP, information extraction systems can process & extract structured information from unstructured text, improve accuracy, contextual understanding & the ability to uncover valuable insights. NLP empowers machines to handle the complexities of language & facilitates the automation & scalability of information extraction tasks in various domains & applications.
Here are some examples of how NLP is used in information extraction:
- Banking: NLP extracts customer information from bank statements & other documents. This information can then be used to prevent fraud & improve customer service.
- Healthcare: NLP extracts medical information from patient records & other documents. This information can then be used to improve diagnosis & treatment.
- Legal: NLP extracts legal information from contracts, statutes & other documents. This information can then be used to provide legal advice & services.
Integration Of Kor With Langchain For Enhanced Information Extraction Capabilities
Here is an example of how Kor and LangChain can be integrated to enhance information extraction capabilities:
import korimport langchain# Initialize Kor for linguistic analysiskor_engine = kor.Engine()# Initialize LangChain for information extractionlangchain_engine = langchain.Engine()# Preprocess and tokenize the input text using Kortext = "The quick brown fox jumps over the lazy dog."preprocessed_text = kor_engine.preprocess(text)tokens = kor_engine.tokenize(preprocessed_text)# Perform linguistic analysis using Korpos_tags = kor_engine.pos_tag(tokens)dependency_tree = kor_engine.dependency_parse(tokens)semantic_roles = kor_engine.semantic_role_label(dependency_tree, pos_tags)coreference_chains = kor_engine.coreference_resolution(tokens)# Perform information extraction using LangChainentities = langchain_engine.extract_named_entities(tokens)relations = langchain_engine.extract_relations(entities, dependency_tree)events = langchain_engine.extract_events(entities, dependency_tree, semantic_roles)sentiment = langchain_engine.analyze_sentiment(preprocessed_text)document_category = langchain_engine.classify_document(preprocessed_text)# Access the extracted informationprint("Named Entities:", entities)print("Relations:", relations)print("Events:", events)print("Sentiment:", sentiment)print("Document Category:", document_category)print("Coreference Chains:", coreference_chains)
In the above code, we first initialize Kor and LangChain engines. We then preprocess the input text using Kor's preprocessing capabilities & tokenize it. Next, we perform linguistic analysis using Kor to obtain part-of-speech tags, dependency trees, semantic roles & coreference chains.
After that, we use LangChain to extract named entities, relations, events, sentiment & document categories from the preprocessed text. Finally, we print out the extracted information, including named entities, relations, events, sentiment analysis, document category & coreference chains.
Conclusion:
Mastering information extraction with LangChain and Kor empowers organizations to efficiently process unstructured text, uncover hidden knowledge & gain a competitive edge. By harnessing their advanced NLP techniques, multilingual support & customizable features, organizations can effectively extract entities, relationships, events & sentiment & categorize documents across diverse domains & contexts.
Hybrowlabs Technology, a leader in advanced AI solutions, offers expertise in harnessing the power of LangChain and Kor for mastering information extraction. With a deep understanding of these tools, Hybrowlabs can assist you in effectively implementing and customizing LangChain and Kor to suit your specific needs. For more information, you can visit Hybrowlabs' Service Page.
FAQ:
1. What is information extraction?
Information extraction is the process of automatically extracting structured & meaningful information from unstructured or semi-structured sources like text documents or web pages.
2. Why is information extraction important?
Information extraction is important for informed decision-making, knowledge discovery, efficient data management, and improved search & retrieval.
3. What are the key challenges in information extraction?
Challenges include ambiguity, named entity recognition, scalability, noisy data, pronouns, coreference, contextual understanding, cross-lingual issues, evaluation & privacy concerns.
4. What role does NLP play in information extraction?
NLP enables machines to understand and extract meaningful information from human language, improving the accuracy & context awareness of information extraction.
5. How can LangChain and Kor help with information extraction?
LangChain offers accurate extraction of named entities, relations, events, sentiment & document classification. Kor provides linguistic analysis to enhance accuracy & contextual understanding.


Similar readings
a3dc85.jpg)
.jpg)

Apoorva
02-11-2025
Advanced RAG 04: Contextual Compressors & Filters
technology
fd8f11.png)

.jpg)
.jpg)
Industries We Serve
