



The 4 Stacks of LLM Apps & Agents
f405da.jpg)
In the ever-evolving world of artificial intelligence and language models, understanding the intricacies of Large Language Model (LLM) apps and agents has become crucial. To navigate this complex landscape, we introduce the concept of the "Four Stacks Framework," which provides a structured approach to comprehend and build LLM applications. In this article, we will explore the Four Stacks Framework, breaking down each stack to demystify the development of LLM apps and agents.
The world of language models has undergone remarkable transformations over the past few years. LLMs, such as OpenAI's GPT-4 and ChatGPT 3.5, have taken center stage in various applications, from chatbots to summarization engines. These models possess incredible capabilities, but harnessing their potential requires a comprehensive understanding of the underlying infrastructure. You can also check our blog on how to create LLM apps with ease of Open source Langchain.
Importance of Understanding the Four Stacks
Why is it essential to grasp the concept of the Four Stacks Framework? Simply put, it acts as a roadmap for anyone venturing into the development of LLM apps and agents. It streamlines the decision-making process, enabling developers to allocate resources effectively and make informed choices at each stage. By understanding the Four Stacks, you can optimize your LLM application for your specific use case.
What are the Four Stacks?

The Four Stacks Framework comprises four fundamental building blocks that work in tandem to create an LLM app or agent. These stacks are:
- The LLM Stack: This forms the base of the framework and deals with everything related to the LLM itself. This includes considerations like pre-training, fine-tuning, and model deployment options.
- Search, Memory, and Data Stack: This stack focuses on acquiring, storing, and retrieving data, as well as memory management, which is crucial for context and in-context learning.
- Reasoning and Action Stack: This layer involves decision-making processes, including the use of models and solvers, to facilitate actions and responses.
- Personalization Stack: The topmost layer, responsible for creating a personalized user experience, encompassing prompt engineering, user tracking, and interaction style customization.
In the following sections, we will delve into each of these stacks, providing a comprehensive understanding of their components and roles in LLM app development.
The LLM Stack

A. Introduction to the LLM Stack
The LLM Stack serves as the foundational layer of the Four Stacks Framework, focusing on the LLM itself. At its core, this stack deals with understanding the LLM's core functionality and its application in various contexts.
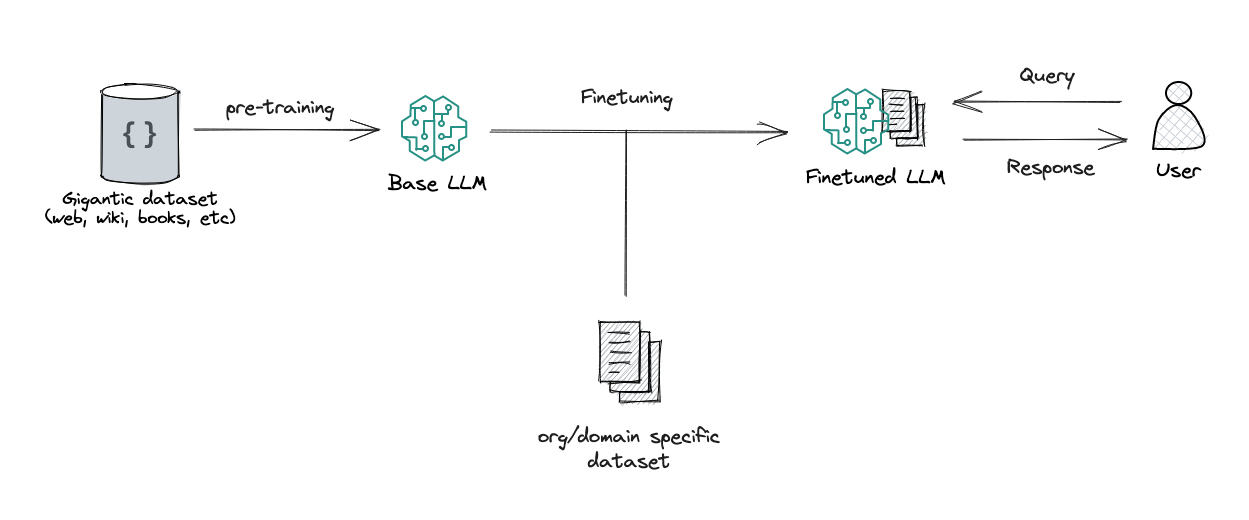
B. Components and Considerations within the LLM Stack
- Pre-training and Fine-tuning: The LLM's journey begins with pre-training, where it learns the language from vast amounts of text data. Fine-tuning tailors the model to specific tasks or domains. Understanding the pre-training process is critical for optimizing your LLM's performance.
- RLHF (Reinforcement Learning from Human Feedback): RLHF helps improve model behavior through reinforcement learning. Utilizing RLHF can refine the model's responses and make them more contextually relevant.
- Custom Fine-tuning: Tailoring the LLM for your specific use case is often essential. Custom fine-tuning allows you to adapt the model to your domain, style, and needs.
- Model Deployment Options: Choosing how and where to deploy your LLM is a critical consideration. Whether you run it in the cloud, on local servers, or on devices can significantly impact performance and accessibility.
C. The Role of the LLM Stack in App Development
The LLM Stack serves as the bedrock upon which LLM applications are built. It dictates the model's behavior and capabilities, influencing the performance and user experience. Understanding the intricacies of this stack is essential for harnessing the full potential of your LLM app or agent.
Search, Memory, and Data Stack
A. Introduction to the Search, Memory, and Data Stack
When delving into the development of Large Language Model (LLM) applications and agents, understanding the Search, Memory, and Data stack is pivotal. This stack forms the bridge between the linguistic prowess of LLMs and the real-world information they need to be truly functional. In this section, we'll explore the intricacies of this stack and how it influences the overall architecture.
B. Components within the Search, Memory, and Data Stack

The cornerstone of any LLM application is its ability to comprehend and retrieve information. Semantic search and vector stores are at the heart of this process. Semantic search techniques enable LLMs to understand the meaning behind queries and documents, facilitating more accurate information retrieval. Vector stores, like Faiss or hosted solutions such as ChromaDB or Pinecone, play a crucial role in storing and retrieving vectors, which are essential for making meaningful connections within the data.
These components allow for not only effective keyword-based searches but also semantic context understanding, making LLMs more proficient in providing relevant responses.
- Data Acquisition and Integration
Acquiring and integrating data from various sources is another key aspect of this stack. LLM applications often need data from conventional databases, knowledge graphs, or other structured sources. Decisions regarding the sources to pull data from, how frequently to update it, and how to maintain data integrity are all part of this critical consideration.
Moreover, the choice of the LLM model itself can affect data integration. Models with larger context windows can accommodate more data, enabling a richer understanding of the information they are processing.
- Real-time Data Retrieval and Scraping
In real-world scenarios, LLM applications often require real-time data, such as the latest news, stock prices, or weather updates. The stack's real-time data retrieval and scraping capabilities facilitate the acquisition of up-to-the-minute information from the web or other sources. Integration with external search engines like Google or DuckDuckGo allows LLMs to fetch live data and incorporate it into their responses.
This aspect is particularly relevant for applications that need to stay updated with constantly changing data or events.
- Memory and In-context Learning
An essential feature, especially for LLM agents, is the ability to remember previous interactions and learn from them. This memory component allows LLMs to store and retrieve context-specific information. It enables agents to understand user preferences and maintain the conversation's flow, making the interaction more personalized and engaging.
C. Interactions with the LLM Stack and Other Stacks
The Search, Memory, and Data stack is closely intertwined with the LLM stack. It provides the LLMs with the information they need to generate responses. Data retrieved from this stack often forms the basis of the prompts given to the LLM, guiding it in delivering relevant and accurate content.
Furthermore, the Search, Memory, and Data stack also interacts with the Reasoning and Action stack. Data retrieved and integrated can influence the decision-making processes within an application or agent. For instance, it might be used in conjunction with solvers to help in solving complex problems or providing recommendations.
In essence, the Search, Memory, and Data stack serves as the informational backbone for LLM applications and agents, ensuring they are well-informed and capable of delivering valuable content to users. Its seamless integration with the other stacks is what enables the creation of intelligent and context-aware applications.
Reasoning and Action Stack
Introduction to the Reasoning and Action Stack
The Reasoning and Action stack represents the brain of LLM applications and agents. While the LLM stack provides linguistic capabilities, and the Search, Memory, and Data stack supplies information, the Reasoning and Action stack empowers LLMs to make decisions, provide solutions, and take actions based on that knowledge. In this section, we will explore this stack and its critical role in LLM app development.
Components and Considerations within the Stack
- Decision-Making and Models
Decision-making is at the heart of LLM applications, and models play a pivotal role in this process. Models within this stack help in making choices, recommendations, and predictions. They enable applications to decide on the most appropriate course of action based on the available data and context. Some LLM applications, like ReAct, utilize models to make decisions autonomously, while others may assist humans in decision-making.
- Solvers and Logic-based Reasoning
A notable aspect of this stack is the use of solvers and logic-based reasoning. These components allow LLM applications to solve complex problems and make logical inferences. They are particularly valuable when precise, rule-based decision-making is required, such as in mathematical problem-solving or logical reasoning tasks.
- Interaction with Tools and APIs
LLM applications often interact with a variety of tools and external APIs to carry out actions. These interactions can range from accessing external databases and services to integrating third-party functionalities. When using these tools, careful consideration is needed to ensure that the LLM's actions align with the desired outcomes.
The Evolving Landscape of Reasoning and Actions in LLM Apps
The Reasoning and Action stack is poised to see significant growth in the future. As LLM technology advances, new ways of reasoning and making decisions beyond large language models are likely to emerge. This could include the development of reasoning engines and more sophisticated solvers. These advancements will enable LLM applications to handle a broader range of tasks and provide even more intelligent responses.
Personalization Stack in LLM Apps
In our exploration of Large Language Model (LLM) apps and agents, we have journeyed through the intricacies of various stacks, each contributing its unique role to the development of these intelligent systems. As we delve into the final segment of our framework, we encounter the Personalization Stack, a crucial element that adds a human touch to LLM applications, creating experiences that are not only informative but also personalized and engaging.
A. Introduction to the Personalization Stack
The Personalization Stack is the pinnacle of LLM app and agent development, where the magic of customization and tailored interactions happens. Here, we focus on making the AI more human-like, enabling it to adapt to different user preferences and contexts. Personalization is about turning a sterile information source into a conversational partner, a tool that understands and responds to its users as individuals.
B. Components and Considerations within the Stack
- Prompt Engineering:
Prompt engineering is the art of crafting the right queries or interactions that elicit desired responses from the LLM. It's about designing prompts that cater to specific tasks and objectives. For instance, if you're building a chatbot for a customer support application, prompt engineering involves constructing inquiries that are friendly, efficient, and in line with the brand's tone.
- User Tracking and Interaction Style:
Understanding your users is at the heart of personalization. LLM apps can track user interactions and behaviors to tailor responses. If a user prefers formal language, a good personalization system will take note and adjust its responses accordingly. It's about making users feel heard and understood.
- Customization and Personality Development:
One of the most exciting aspects of personalization is giving your LLM app or agent a unique personality. This is where you can make your AI friendly, humorous, serious, or even quirky, depending on the intended audience and application. Personality development includes determining the AI's tone, quirks, and even its sense of humor. It's about creating a brand identity and establishing a connection with users.
C. The Role of Personalization in Creating Unique LLM Experiences

The personalization stack plays a pivotal role in creating memorable LLM experiences. It's the layer that transforms a mere tool into a trusted assistant. Personalization ensures that the LLM understands its users at a deeper level and can anticipate their needs. Here are some key roles it plays:
- Enhancing User Engagement: Personalization makes interactions more engaging. Users are more likely to continue conversations and derive value when the AI responds in a personalized and relatable manner.
- Building Brand Loyalty: For businesses, personalization is a valuable tool for building brand loyalty. A well-personalized LLM can embody a brand's voice, making interactions with users not just helpful but also on-brand.
- Adapting to Different Contexts: The ability to adapt to different user contexts is a hallmark of personalization. Whether it's a user's mood, preferences, or previous interactions, the LLM can adjust its responses to suit the moment.
- Creating Unique Experiences: Personalization enables LLM apps to create unique experiences for each user. From recommending products that match a user's taste to delivering content in a style that resonates with them, the AI can curate experiences that stand out.
Integrating the Stacks
In the realm of Large Language Model (LLM) applications and agents, creating a seamless and functional system often relies on the effective integration of four critical stacks. These four stacks include the LLM Stack, the Search, Memory, and Data Stack, the Reasoning and Action Stack, and the Personalization Stack. In this segment, we will dive into the integration of these stacks, uncovering how they collaborate to form powerful LLM applications and agents.
A. Understanding the Interplay Between the Stacks
The four stacks, while distinct in their functions, do not operate in isolation. Instead, they work in harmony, each stack complementing and augmenting the capabilities of the others. Understanding how these stacks interact is fundamental to the successful development of LLM applications.
- LLM Stack's Role: The LLM Stack forms the foundation, as it houses the core language model. This model is the engine that processes and generates text-based responses. It acts as the gateway for input and output in the entire system.
- Data Feeds the System: The Search, Memory, and Data Stack are closely intertwined with the LLM Stack. Data acquired, stored, and retrieved from this stack fuels the LLM with valuable information, enhancing its response capabilities.
- Reasoning and Decision-making: The Reasoning and Action Stack, in conjunction with the LLM, contributes to decision-making processes. It allows the system to make informed choices based on the context and requirements, using a combination of logic, mathematics, and machine learning.
- Personalization for a Human Touch: The Personalization Stack adds a layer of human-like interaction, ensuring that the responses from the LLM are customized to match the desired style, personality, and brand identity.
B. The Impact of Stack Choices on App or Agent Design
The choices made regarding the composition and integration of these stacks have a significant impact on the design and functionality of LLM applications and agents.
- Scalability and Performance: The LLM Stack's choice directly affects the scalability and performance of the application. Fine-tuning and deployment options determine how well the system adapts to the required tasks.
- Data Sources and Integration: The Search, Memory, and Data Stack dictates the variety and sources of data that can be accessed. Decisions on vector stores, data retrieval methods, and memory management impact the breadth and depth of knowledge the LLM can access.
- Logic and Decision-making Capability: The Reasoning and Action Stack introduces the system's decision-making abilities. The choice of reasoning engines, solvers, and APIs can make or break the system's ability to perform complex tasks effectively.
- User Experience and Branding: The Personalization Stack influences the user experience. How well the system can be tailored to specific user preferences, conversation styles, and brand identity significantly impacts user engagement and satisfaction.
C. Tools and Platforms that Facilitate Stack Integration
Efficient integration of the four stacks requires a range of tools and platforms that streamline the development process.
- LLM Model Frameworks: Leveraging established LLM model frameworks like GPT-4, ChatGPT 3.5, or LLaMA-2 provides a strong starting point. The choice of framework can be influenced by the specific needs of the application.
- Data Integration Services: Utilizing data integration services and platforms, such as Faiss, ChromaDB, or Pinecone, streamlines data acquisition and retrieval from various sources.
- Reasoning Engines and APIs: Access to reasoning engines, mathematical solvers, and APIs for specific functionalities is vital for building systems capable of complex decision-making.
- Personalization Tools: There are tools available for prompt engineering, conversation style customization, and user tracking, allowing developers to create personalized, engaging interactions.
Practical Application of LLM Stacks
A. How to use the four stacks framework for LLM app and agent development
Building Large Language Model (LLM) applications and agents may sound complex, but the four stacks framework simplifies the process, making it more manageable. In this section, we will explore how to utilize the framework effectively for LLM app and agent development.
- Understanding Your Objectives:
Begin by clearly defining your goals and objectives for the LLM application or agent. What do you want it to achieve? Understanding this is the first step in determining which stacks will be most critical for your project.
- Selecting the Right Model:
Evaluate your needs to decide which LLM model suits your project. You can choose from various models like OpenAI's GPT-4, ChatGPT 3.5, or LLaMA-2. Your choice will largely depend on your specific use case and the desired scale of the application.
- Stack Customization:
Tailor each stack to your project's requirements. Consider the options available for pre-training, fine-tuning, and potential reinforcement learning from human feedback (RLHF). These choices directly impact your model's performance.
- Deployment Strategy:
Determine how you will deploy your LLM model. Will you use cloud-based solutions, local installations, or both? The decision will affect factors like scalability, cost, and accessibility.
B. Tailoring the Framework to Specific Use Cases
No two LLM applications or agents are the same. To make the most of the four stacks framework, you need to tailor it to your specific use case. Here's how:
- Identify Your Use Case:
Clearly define your use case. Are you developing a chatbot, a summarization tool, or something entirely unique? The nature of your application will influence how you allocate resources among the four stacks.
- Emphasize Key Stacks:
Recognize which stacks are paramount for your use case. For instance, if you're developing a chatbot, the personalization stack may be of utmost importance, while a data-intensive research tool may require a strong focus on the search, memory, and data stack.
- Model and Stack Compatibility:
Ensure that the chosen LLM model aligns with your specific use case. Some applications may require models with larger context windows, while others may thrive with more lightweight alternatives.
- Budget and Resource Allocation:
Allocate your resources judiciously based on your project's requirements. This includes both financial and human resources. The more customized your approach, the more efficient your LLM app or agent will be.
C. Examples of Real-World Applications and Their Stack Configurations
To illustrate the effectiveness of the four stacks framework, let's delve into real-world examples of LLM applications and agents and the configurations they employ:
- Customer Support Chatbot:
For a customer support chatbot, the LLM stack includes an easily adaptable model for handling a variety of inquiries. The search, memory, and data stack incorporates real-time data retrieval to answer customer queries accurately. Personalization ensures the chatbot's tone and style align with the company's brand.
- Legal Document Summarization Tool:
In a legal document summarization tool, the emphasis is on reasoning and action. The LLM model is fine-tuned to understand legal jargon, and a reasoning engine aids in extracting critical information. This application may not require extensive personalization, but it must excel in data retrieval.
- AI-Powered Virtual Personal Assistant:
Personalization takes center stage in this application. The LLM model is designed to mimic a specific personality and provide tailored responses. The search, memory, and data stack assist in accessing personal user data securely, while the reasoning and action stack facilitates tasks like scheduling and reminders.
These examples demonstrate how the four stacks framework can be applied to diverse use cases, highlighting the flexibility and adaptability of LLM applications and agents.
Conclusion
In the world of Large Language Model (LLM) applications and agents, understanding the intricate workings of these AI-driven systems is key to their successful development. The Four Stacks Framework provides a structured approach to dissecting and comprehending these complex entities. From the foundation of the LLM stack to the layers of search, memory, data, reasoning, and personalization, each element plays a vital role in crafting powerful LLM applications. As we look toward the future, this framework will undoubtedly evolve as new technologies and capabilities emerge, continually shaping the landscape of AI-powered apps and agents. For more information related to LLM Applications, visit hybrowlabs official website today.
FAQ
1. What is the Four Stacks Framework for LLM apps and agents?
The Four Stacks Framework is a structured model for dissecting LLM applications, comprising the LLM, Search, Memory and Data, Reasoning and Action, and Personalization stacks.
2. What role does the LLM stack play in this framework?
The LLM stack is the foundation, encompassing factors like pre-training, fine-tuning, RLHF, and deployment options for the language model.
3. How does the Search, Memory, and Data stack contribute to LLM apps and agents?
This stack deals with data acquisition, real-time information retrieval, and memory, crucial for enhancing LLM interactions.
4. What's the significance of the Reasoning and Action stack?
It focuses on decision-making, logic-based reasoning, and interaction with tools and APIs, enriching the LLM's decision-making capabilities.
5. What does the Personalization stack entail?
The Personalization stack involves prompt engineering, user tracking, and customization, which shape the LLM's style, personality, and responses.

Similar readings
a3dc85.jpg)
.jpg)

Apoorva
22-11-2025
Advanced RAG 04: Contextual Compressors & Filters
technology
fd8f11.png)


.jpg)
.jpg)
Industries We Serve
