



Knowledge Retrieval Assistants Over Sops, Contracts, And Technical Manuals For Erpnext
Knowledge retrieval assistants over SOPs, contracts, and technical manuals can become a strategic capability for ERPNext organizations when implemented as a governed retrieval system rather than a generic chatbot. This deep-dive whitepaper covers architecture, data modeling, retrieval quality, security controls, implementation blueprint, and production readiness patterns for enterprise deployments.
Executive summary
ERPNext deployments often run high-value workflows where answer quality directly affects compliance, customer trust, and operating cost. Teams need fast answers to policy-heavy questions, but document sprawl across SOPs, contracts, manuals, tickets, and attachments makes this difficult. A retrieval assistant solves this by grounding every answer in approved evidence and preserving full traceability from user question to cited source.
Core design principle: No citation, no answer.
System architecture (ERPNext-centered)
The recommended architecture is built as a custom app around ERPNext-native records and permissions.

Architectural layers
Experience layer
- ERPNext Desk, Portal, or embedded widget
- Query templates by role (legal, support, operations)
Application layer
- Retrieval Assistant API (custom app endpoints)
- Policy engine for access and answer constraints
Retrieval layer
- Hybrid retrieval (keyword + semantic vectors)
- Re-ranking using authority, recency, and confidence
Knowledge layer
- Parsed and chunked corpus with metadata
- Clause-aware contract indexing and section-aware SOP indexing
Governance layer
- Audit trail, evidence map, and response logs
- Feedback and correction workflow with human review
2.1 Architecture Diagram
Below is a full enterprise-style architecture view for permission-aware RAG over SOPs, contracts, and technical manuals in ERPNext.
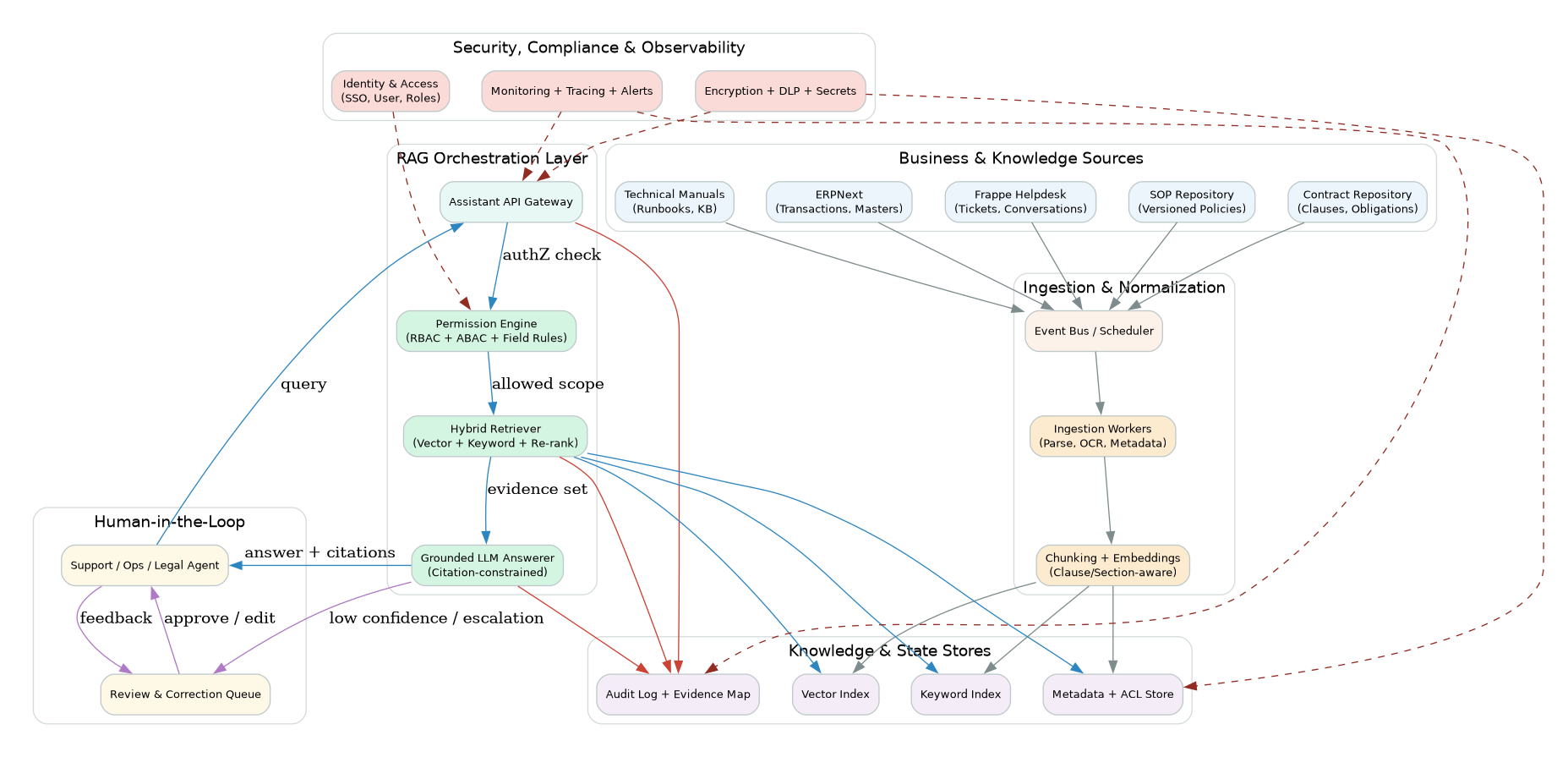
AWS reference architecture (enterprise deployment)
For teams deploying on AWS, the following reference design maps permission-aware RAG controls to managed services while preserving auditability and scale.

Key implementation notes: - API edge hardening via WAF + API Gateway + ALB - RAG orchestrator on ECS/EKS with permission checks before retrieval - OpenSearch for hybrid retrieval index, Aurora PostgreSQL for ACL + metadata + logs - S3 as governed source repository with event-driven ingestion workers (Lambda) - IAM + KMS + Secrets Manager for security posture - CloudWatch/CloudTrail for observability and forensic traceability
In-depth query lifecycle
A production system needs deterministic stages for explainability and reliability.
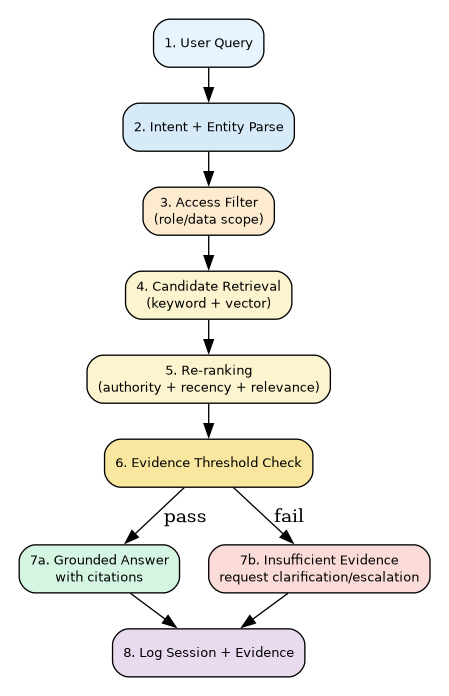
Stage-by-stage flow
Query capture
- Capture user prompt, role, department, tenant, and context references.
Intent and entity parsing
- Extract entities such as vendor names, clause IDs, SOP codes, DocTypes, version tags.
Access scoping before retrieval
- Enforce role policies before candidate retrieval to avoid leakage.
Candidate retrieval
- Run hybrid search over indexed corpus.
- Include lexical boosts for exact clause IDs and policy numbers.
Re-ranking
- Compute rank score from relevance + source authority + recency + policy status.
Evidence threshold gate
- If citation confidence is low, return “insufficient evidence” and request clarifying input.
Grounded response generation
- Generate only from selected evidence chunks.
- Attach source references (document, section, clause/page).
Post-response logging
- Persist evidence map, final answer, confidence, and user feedback path.
Data modeling for SOPs, contracts, and manuals
Why document-type-aware indexing matters
Different content classes need different chunking rules:
- SOPs: section/procedure-step chunking, role-owner metadata, effective date metadata
- Contracts: clause-boundary chunking, legal obligation tags, notice/cure period extraction
- Technical manuals: heading + command/procedure block chunking, version binding
Recommended metadata schema
Each chunk should include: - sourceid, sourcetype (SOP/Contract/Manual) - documenttitle, version, effectivedate - ownerdepartment, confidentialitylevel - approvalstatus (draft/approved/retired) - clauseorsectionid - pagereference - tenant / businessunit scope
Version and lifecycle control
- Only “approved” versions should be retrieval-default.
- Retired versions remain searchable only with explicit “historical mode.”
- Index refresh must be event-driven on document update.
Retrieval quality engineering
Retrieval strategy
Use a weighted hybrid strategy: - 40% lexical BM25 relevance - 40% vector similarity - 20% authority/recency signals
Authority scoring signals
- Approved status boost
- Department-owner confidence boost
- Recency decay for outdated technical docs
- Penalty for drafts and unverified uploads
Quality guardrails
- Enforce minimum citation count for critical answer classes.
- Block unsupported normative claims (“must/shall”) without source clauses.
- Prefer explicit quotation snippets for legal-sensitive responses.
Security and governance deep dive
Enterprise reliability depends on layered controls.

Control stack
Identity layer
- ERPNext user + role context
- SSO integration where available
Authorization layer
- RBAC for broad role boundaries
- ABAC for document tags (department, confidentiality, tenant)
Data control layer
- Encryption at rest and in transit
- Retention policy by source class and regulation
- Sensitive-field masking in non-privileged responses
Model safety layer
- Prompt injection filters on untrusted source text
- Strict no-fabrication policy under low evidence
Operational governance
- Human-in-the-loop review queues
- Error taxonomy and correction workflows
- KPI dashboarding and periodic policy audits
ERPNext implementation blueprint
Custom app modules
knowledge_registry(source catalog + ownership)index_jobs(ingest/reindex pipeline)retrieval_api(query endpoint)evidence_log(traceability record)feedback_queue(corrections + review)
Recommended custom DocTypes
- Knowledge Source Registry
- Knowledge Chunk Metadata
- Retrieval Session Log
- Citation Evidence Map
- Review and Correction Task
Integration hooks
- On file/document update → enqueue re-index job
- On retrieval response → persist evidence log
- On negative feedback → create correction task
Deployment topologies
Option A: ERPNext app + managed retrieval services
Fastest to production; suitable for teams prioritizing speed and lower ops overhead.
Option B: Fully self-hosted retrieval stack
Best for strict data residency/compliance; higher platform ownership cost.
Option C: Hybrid
Sensitive indexes self-hosted; low-risk corpora on managed infra.
Performance and SRE targets
Suggested SLOs
- P95 query latency: < 2.5s for standard queries
- Citation coverage: > 98% for policy/legal categories
- Grounding accuracy (audited sample): > 95%
- Unauthorized retrieval incidents: 0
Reliability patterns
- Queue-based ingestion with retries and dead-letter handling
- Blue/green index swaps for zero-downtime reindexing
- Circuit breakers on model timeout and retrieval fallback paths
Observability and auditability
A production implementation should expose: - Query volume by department/use case - Top unanswered intents (for content gap closure) - Low-confidence response rate - Source freshness and stale-document impact - Correction turnaround time and repeat error rate
12-week rollout plan
Weeks 1-2: Discovery and policy baseline
- Corpus inventory, ownership mapping, access matrix
- Define answer classes and evidence thresholds
Weeks 3-5: Foundation build
- Ingestion pipeline + metadata + hybrid index
- ERPNext app scaffolding and role-aware query endpoint
Weeks 6-8: Pilot
- Launch for one business function (support/legal)
- Enable feedback queue and daily tuning cycle
Weeks 9-10: Governance hardening
- Add audit dashboards, redaction checks, exception handling
- Conduct structured factuality and access tests
Weeks 11-12: Scale-out
- Expand to multi-team usage
- Publish operational runbook and ownership model
Anti-patterns to avoid
- Using raw LLM chat without retrieval evidence enforcement
- Mixing drafts and approved policies in the same retrieval priority
- Ignoring role-scoped retrieval filters
- Shipping without correction and feedback workflows
- Treating “answer fluency” as success instead of grounded correctness
Conclusion
For ERPNext organizations, knowledge retrieval assistants deliver the highest value when built as a governed, citation-first system with ERP-native traceability. With the right architecture and controls, they can substantially improve response quality, reduce decision latency, and strengthen compliance posture across SOP, contract, and technical-manual workflows.
